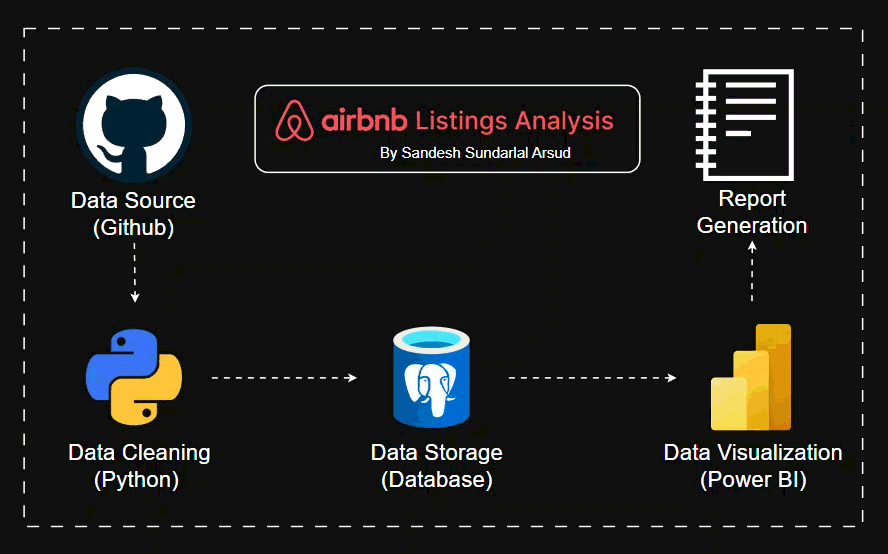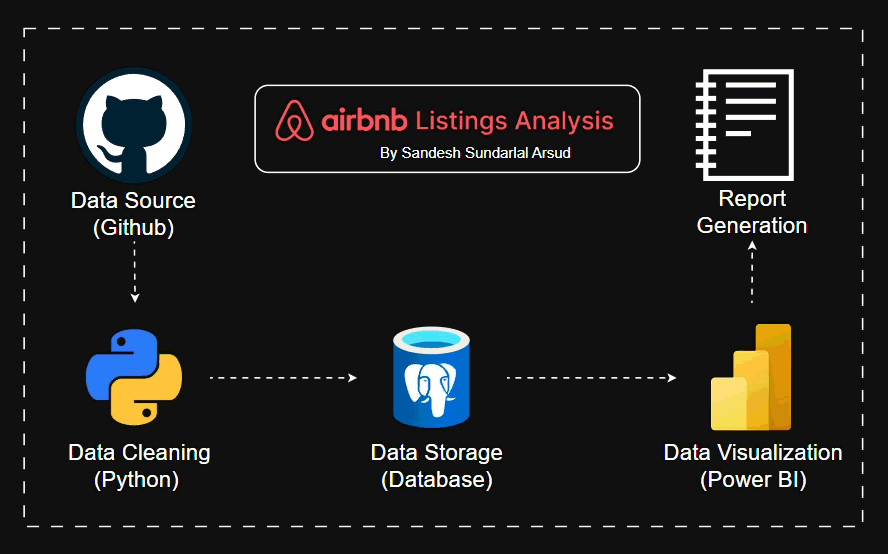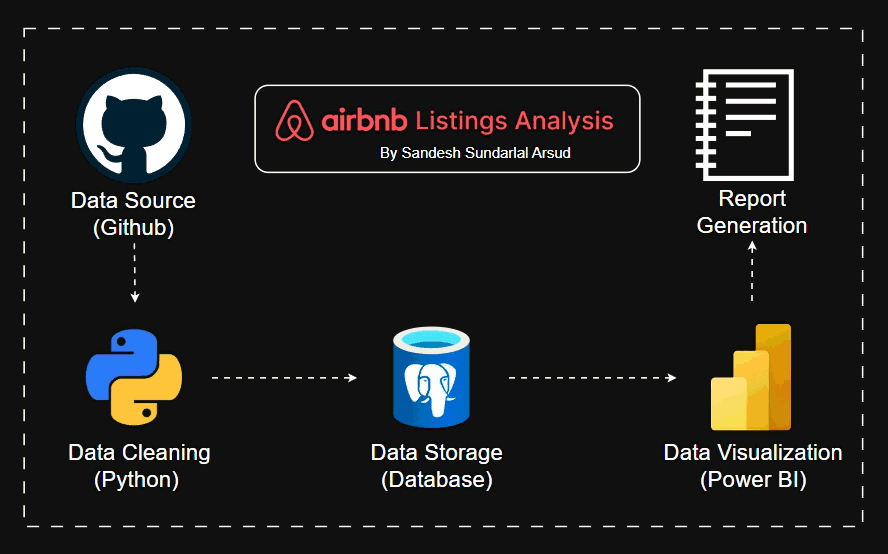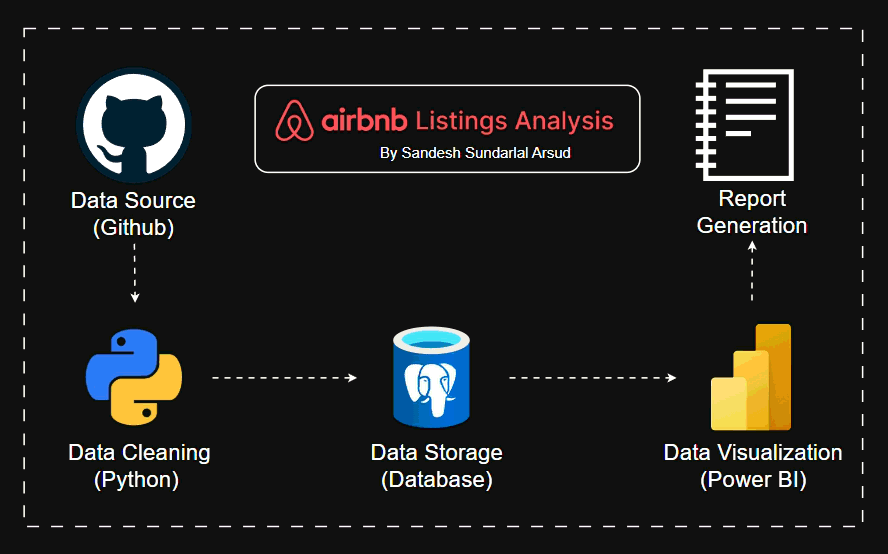
End to end Airbnb Data Analysis
PythonSQLPower BI
Airbnb Data Analysis
Project Overview
This project focuses on preparing the Airbnb Listings Dataset for structured analysis. The work includes data exploration, cleaning, handling missing values, and feature engineering to ensure the dataset is reliable for analytical or predictive tasks.
Dataset Information
The dataset contains detailed information on listings, hosts, pricing, and availability across multiple locations. It forms the base for exploration, feature creation, and deriving market insights.
| Attribute | Description |
|---|---|
| Dataset Name | Airbnb NYC |
| Source | Github |
| File Format | CSV |
| Number of Records | 48,895 |
| Key Columns | 'id', 'name', 'host_id', 'neighbourhood', 'room_type', 'price', 'availability_365', 'reviews_per_month' |
Project Objectives
- Clean and preprocess the dataset to resolve inconsistencies and missing values.
- Build meaningful features that enhance analytical and modeling outcomes.
- Use visualizations to uncover insights and trends.
- Generate a clean, analysis-ready dataset for machine learning or reporting.
Tools and Libraries
- Python
- Pandas, NumPy for data manipulation
- Matplotlib, Seaborn for visualization
- SQLAlchemy, urllib for connectivity
- dotenv, os for environment management
- Jupyter Notebook for development
Methodology
- Import required Python libraries.
- Load the dataset from a reliable source.
- Explore data distributions and identify patterns or anomalies.
- Clean data by handling missing values, duplicates, and inconsistencies.
- Engineer new features for better interpretability.
- Export the cleaned dataset for downstream use.

Results Summary
- The dataset was cleaned and validated for consistency.
- Missing values were handled using suitable strategies.
- Feature engineering improved the dataset’s structure and interpretability.
- The final dataset is ready for exploratory analysis and predictive modeling.
- A clean, exportable version of the dataset has been prepared for future workflows.